



The cover image is from NASA’s James Webb Space Telescope called “Cosmic Cliffs” in the Carina Nebula.
Definition of Operating system


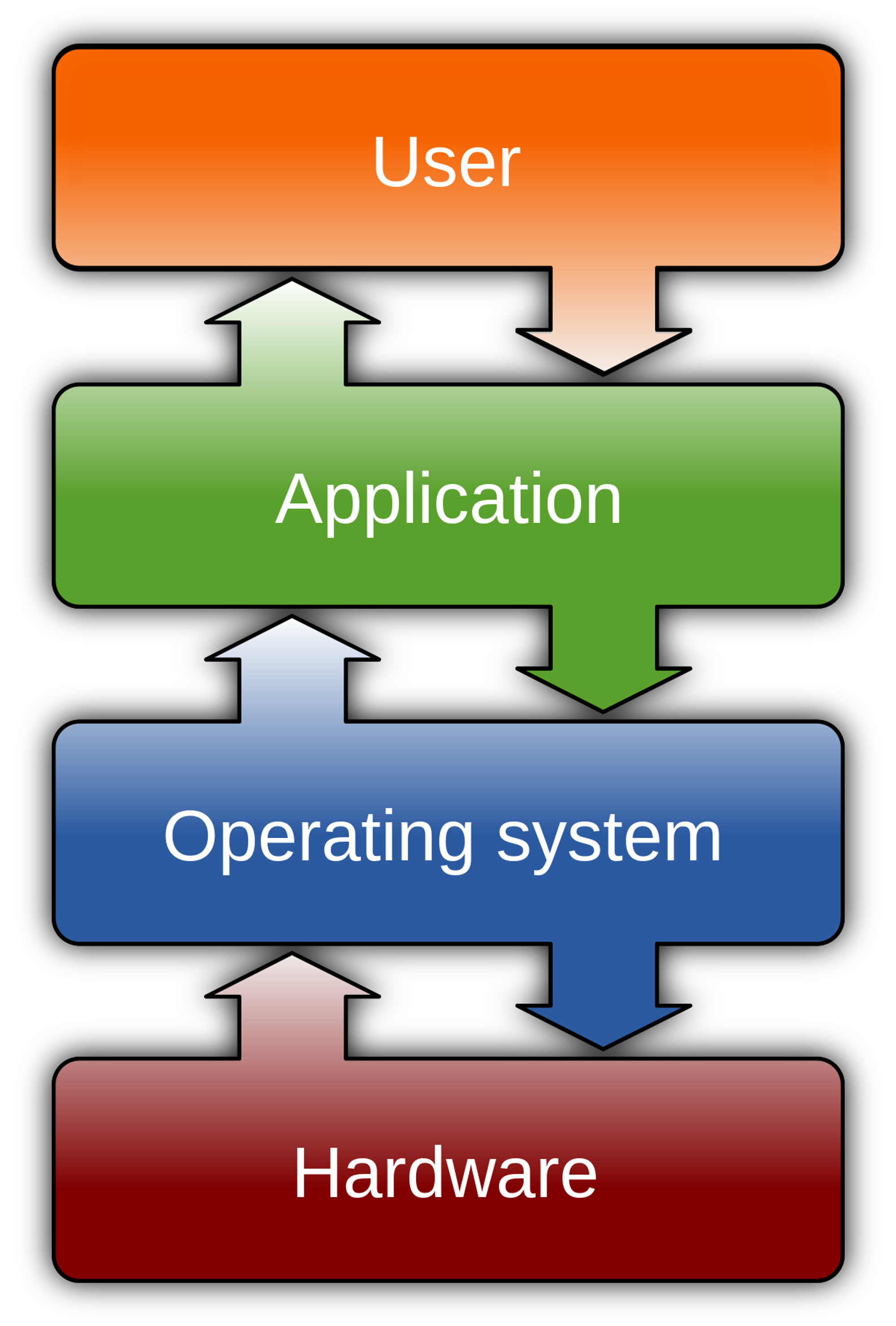
An Operating System is a software that manages both application and hardware resources.
Types of Operating Systems
- Multi-programming OS – The main memory consists of jobs waiting for CPU time. The OS selects one of the processes and assigns it to the CPU. Whenever the executing process needs to wait for any other operation (like I/O), the OS selects another process from the job queue and assigns it to the CPU. This way, the CPU is never kept idle and the user gets the flavor of getting multiple tasks done at once.
- Batch OS – A set of similar jobs are stored in the main memory for execution. A job gets assigned to the CPU, only when the execution of the previous job completes.
- Multitasking OS – Multitasking OS combines the benefits of Multi-programming OS and CPU scheduling to perform quick switches between jobs. The switch is so quick that the user can interact with each program as it runs
- Time Sharing OS – Time-sharing systems require interaction with the user to instruct the OS to perform various tasks. The OS responds with an output. The instructions are usually given through an input device like the keyboard.
- Real Time OS – Real-Time OS are usually built for dedicated systems to accomplish a specific set of tasks within deadlines.
User Mode
In user mode, processes do not have direct access to the RAM or other hardware resources and have to make system calls to the underlying APIs to access these resources.
Kernel Mode
In kernel mode, system starts in the kernel mode when it boots up. The kernel mode has direct access to all the underlying hardware resources. In the kernel mode, all memory addresses are accessible and all CPU instructions are executable.
Process

.png%3Ftable%3Dblock%26id%3Defbae7b7-40c3-4beb-8915-2c5f8a484ae5%26cache%3Dv2&w=3840&q=75)
A process is a program under execution. The value of program counter (PC) indicates the address of the next instruction of the process being executed. Each process is represented by a Process Control Block (PCB).
- New − The process is being created.
- Ready − The process is waiting to be assigned to a processor.
- Running − In this state the instructions are being executed.
- Waiting − The process is in waiting state until an event occurs like I/O operation completion or receiving a signal.
- Terminated − The process has finished execution.
Operations on Process
1. Creation: This the initial step of process execution activity. Process creation means the construction of a new process for the execution. This might be performed by system, user or
old process itself. There are several events that leads to the process creation. Some of the such events are following:
- When we start the computer, system creates several background processes.
- A user may request to create a new process.
- A process can create a new process itself while executing.
- Batch system takes initiation of a batch job.
2. Scheduling/Dispatching:
The event or activity in which the state of the process is changed from ready to running. It means the operating system puts the process from ready state into the running state. Dispatching is done by operating system when the resources are free or the process has higher priority than the ongoing process. There are various other cases in which the process in running state is preempted and process in ready state is dispatched by the operating system.
3. Blocking:
When a process invokes an input-output system call that blocks the process and operating system put in block mode. Block mode is basically a mode where process waits for input-output. Hence on the demand of process itself, operating system blocks the process and dispatches another process to the processor. Hence, in process blocking operation, the operating system puts the process in ‘waiting’ state.
4. Preemption:
When a timeout occurs that means the process hadn’t been terminated in the allotted time interval and next process is ready to execute, then the operating system preempts the process. This operation is only valid where CPU scheduling supports preemption. Basically this happens in priority scheduling where on the incoming of high priority process the ongoing process is preempted. Hence, in process preemption operation, the operating system puts the process in ‘ready’ state.
5. Termination:
Process termination is the activity of ending the process. In other words, process termination is the relaxation of computer resources taken by the process for the execution. Like creation, in termination also there may be several events that may lead to the process termination.
Some of them are:
- Process completes its execution fully and it indicates to the OS that it has finished.
- Operating system itself terminates the process due to service errors.
- There may be problem in hardware that terminates the process.
- One process can be terminated by another process.
Semaphores
Semaphores are integer variables that are used to solve the critical section problem by using two atomic operations, wait and signal that are used for process synchronization.
Types of Semaphores
There are two main types of semaphores Counting Semaphores and Binary Semaphores
- Counting Semaphores
These are integer value semaphores and have an unrestricted value domain.
These semaphores are used to coordinate the resource access, where the semaphore count is the number of available resources. If the resources are added, semaphore count automatically incremented and if the resources are removed, the count is decremented.
- Binary Semaphores
The binary semaphores are like counting semaphores but their value is
restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0. It is sometimes easier to implement binary semaphores than counting semaphores.
Peterson’s Algorithm
Peterson's algorithm (or Peterson's solution) is a concurrent programming algorithm for mutual exclusion that allows two or more processes to share a single-use resource without conflict, using only shared memory for communication. It was formulated by Gary L. Peterson in 1981. While Peterson's original formulation worked with only two processes, the algorithm can be generalized for more than two.
The algorithm uses two variables:
flag and turn. A flag[n] value of true indicates that the process n wants to enter the critical section. Entrance to the critical section is granted for process P0 if P1 does not want to enter its critical section and if P1 has given priority to P0 by setting turn to 0.Schedulers
The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.
Different types of schedulers
- Long Term Schedulers - Long term scheduler is also known as job scheduler. It chooses the processes from the pool (secondary memory) and keeps them in the ready queue maintained in the primary memory. Long Term scheduler mainly controls the degree of Multi-programming. The purpose of long term scheduler is to choose a perfect mix of IO bound and CPU bound processes among the jobs present in the pool.
- Medium Term Schedulers - Medium term scheduler takes care of the swapped out processes.If the running state processes needs some IO time for the completion then there is a need to change its state from running to waiting. Medium term scheduler is used for this purpose. It removes the process from the running state to make room for the other processes. Such processes are the swapped out processes and this procedure is called swapping. The medium term scheduler is responsible for suspending and resuming the processes. It reduces the degree of multi-programming. The swapping is necessary to have a perfect mix of processes in the ready queue.
- Short Term Schedulers - Short term scheduler is also known as CPU scheduler. It selects one of the Jobs from the ready queue and dispatch to the CPU for the execution. A scheduling algorithm is used to select which job is going to be dispatched for the execution. The Job of the short term scheduler can be very critical in the sense that if it selects job whose CPU burst time is very high then all the jobs after that, will have to wait in the ready queue for a very long time. This problem is called starvation which may arise if the short term scheduler makes some mistakes while selecting the job.
Degree of multi-programing
- The degree of multi-programming describes the maximum number of processes that a single-processor system can accommodate efficiently
- The primary factor affecting the degree of multi-programming is the amount of memory available to be allocated to executing processes.
System calls
System calls are usually made when a process in user mode requires access to a resource. Then it requests the kernel to provide the resource via a system call.
Types of system calls


Process Control
These system calls deal with processes such as process creation, process termination etc.
File Management
These system calls are responsible for file manipulation such as creating a file, reading a file, writing into a file etc.
Device Management
These system calls are responsible for device manipulation such as reading from device buffers, writing into device buffers etc.
Information Maintenance
These system calls handle information and its transfer between the operating system and the user program.
Communication
These system calls are useful for inter-process communication. They also deal with creating and deleting a communication connection.
Important System Calls Used in OS
wait():
In some systems, a process needs to wait for another process to complete its execution. This type of situation occurs when a parent process creates a child process, and the execution of the parent process remains suspended until its child process executes.The suspension of the parent process automatically occurs with a wait() system call. When the child process ends execution, the control moves back to the parent process.
fork():
Processes use this system call to create processes that are a copy of themselves. With the help of this system Call parent process creates a child process, and the execution of the parent process will be suspended till the child process executes.
exec():
This system call runs when an executable file in the context of an already running process that replaces the older executable file. However, the original process identifier remains as a new process is not built, but stack, data, head, data, etc. are replaced by the new process.
kill():
The kill() system call is used by OS to send a termination signal to a process that urges the process to exit. However, a kill system call does not necessarily mean killing the process and can have various meanings.
exit():
The exit() system call is used to terminate program execution. Specially in the multi-threaded environment, this call defines that the thread execution is complete. The OS reclaims resources that were used by the process after the use of exit() system call.
CPU Scheduling
CPU Scheduling is a process of determining which process will own CPU for execution while another process is on hold. The main task of CPU scheduling is to make sure that whenever the CPU remains idle, the OS at least select one of the processes available in the ready queue for execution. The selection process will be carried out by the CPU scheduler. It selects one of the processes in memory that are ready for execution.
Types of CPU Scheduling

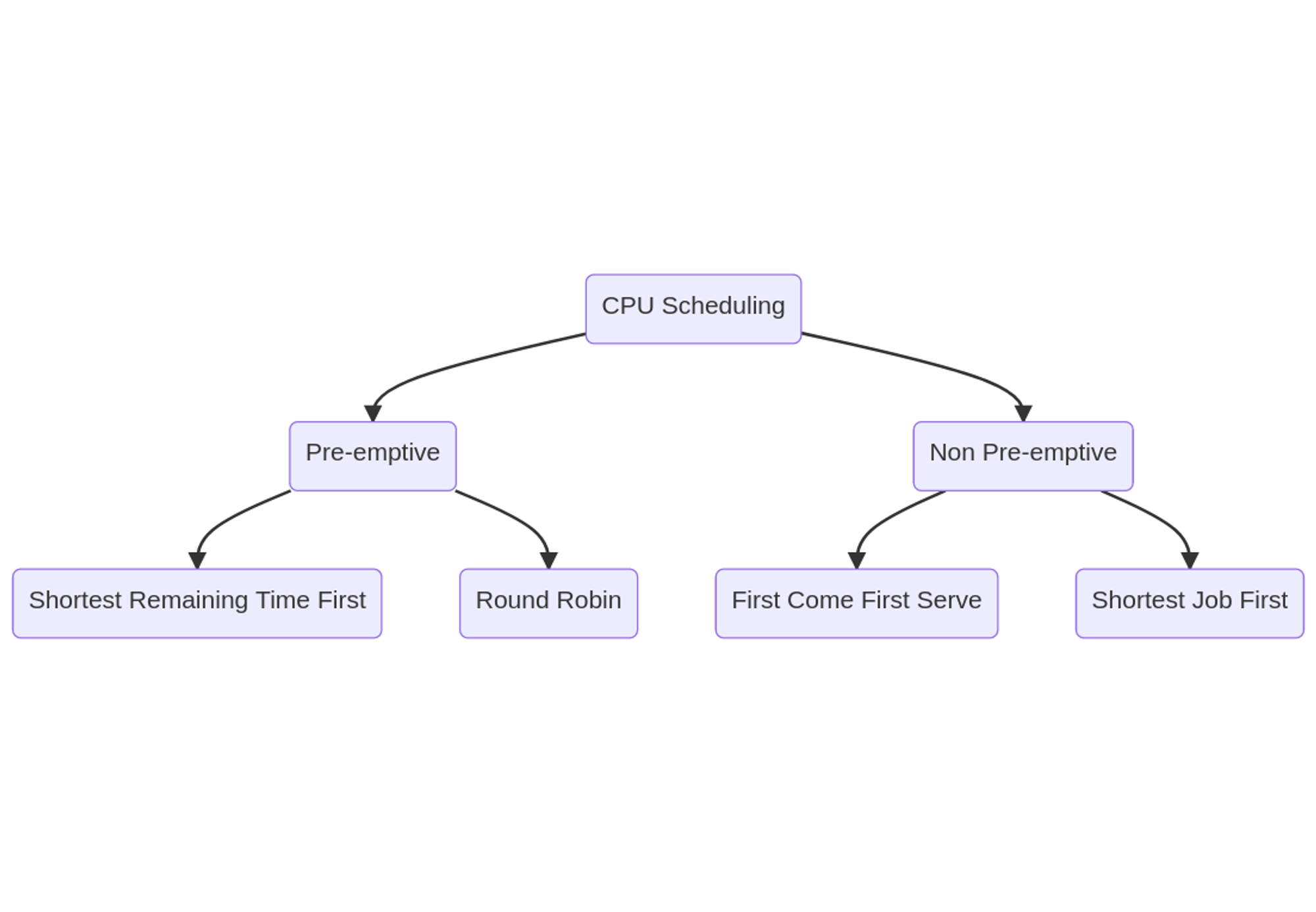
Preemptive Scheduling
In Preemptive Scheduling, the tasks are mostly assigned with their priorities. Sometimes it is important to run a task with a higher priority before another lower priority task, even if the lower priority task is still running. The lower priority task holds for some time and resumes when the higher priority task finishes its execution.
Non-Preemptive Scheduling
In this type of scheduling method, the CPU has been allocated to a specific process. The process that keeps the CPU busy will release the CPU either by switching context or terminating. It is the only method that can be used for various hardware platforms. That’s because it doesn’t need special hardware (for example, a timer) like preemptive scheduling.
Important Terms
- Arrival Time – Time at which the process arrives in the ready queue.
- Completion Time – Time at which process completes its execution.
- Burst Time – Time required by a process for CPU execution.
- Turn Around Time – Time Difference between completion time and arrival time.
- Waiting Time (WT) – Time Difference between turn around time and burst time.
CPU Scheduling Algorithm
- The CPU uses scheduling to improve its efficiency.
- It helps you to allocate resources among competing processes.
- The maximum utilization of CPU can be obtained with multi-programming.
- The processes which are to be executed are in ready queue.
First Come First Serve
First come, first served is a scheduling algorithm where processes are put into a queue and then executed in the order that they arrive.
As the process enters the ready queue, its PCB (Process Control Block) is linked with the tail of the queue. So, when CPU becomes free, it should be assigned to the process at the beginning of the queue.
Characteristics of FCFS method:
- It offers non-preemptive and pre-emptive scheduling algorithm.
- Jobs are always executed on a first-come, first-serve basis
- It is easy to implement and use.
- However, this method is poor in performance, and the general wait time is quite high.
Shortest Remaining Time
The full form of SRT is Shortest remaining time. It is also known as SJF preemptive scheduling. In this method, the process will be allocated to the task, which is closest to its completion. This method prevents a newer ready state process from holding the completion of an older process.
Characteristics of SRT scheduling method:
- This method is mostly applied in batch environments where short jobs are required to be given preference.
- This is not an ideal method to implement it in a shared system where the required CPU time is unknown.
- Associate with each process as the length of its next CPU burst. So that operating system uses these lengths, which helps to schedule the process with the shortest possible time.
Shortest Job First
Shortest job first is a scheduling algorithm that prioritizes running the process with the shortest execution time first. It is also know as SJF.
Characteristics of SJF Scheduling
- It is associated with each job as a unit of time to complete.
- In this method, when the CPU is available, the next process or job with the shortest completion time will be executed first.
- It is Implemented with non-preemptive policy.
- This algorithm method is useful for batch-type processing, where waiting for jobs to complete is not critical.
- It improves job output by offering shorter jobs, which should be executed first, which mostly have a shorter turnaround time.
Round Robin
Round robin is a scheduling algorithm where a fixed amount of time is chosen and assigned to each process. The scheduler then cycles through all of these processes until they are all completed. Processes that do not finish during their assigned time are rescheduled to allow all other processes an opportunity to run first.
Characteristics of Round-Robin Scheduling
- Round robin is a hybrid model which is clock-driven
- Time slice should be minimum, which is assigned for a specific task to be processed. However, it may vary for different processes.
- It is a real time system which responds to the event within a specific time limit.
Deadlock
A deadlock is a situation in which more than one process is blocked because it is holding a resource and also requires some resource that is acquired by some other process. Therefore, none of the processes gets executed.
Banker’s Algorithm
Banker’s Algorithm is a deadlock avoidance algorithm. It is also used for deadlock detection. This algorithm tells that if any system can go into a deadlock or not by analyzing the currently allocated resources and the resources required by it in the future. There are various data structures which are used to implement this algorithm. So, let's learn about these first.
File System
A file is a collection of related information that is recorded on secondary storage. Or file is a collection of logically related entities. From user’s perspective a file is the smallest allotment of logical secondary storage.
File Directory
Collection of files is a file directory. The directory contains information about the files, including attributes, location and ownership. Much of this information, especially that is concerned with
storage, is managed by the operating system. The directory is itself a file, accessible by various file management routines.
Information contained in a device directory are:
- Name
- Type
- Address
- Current length
- Maximum length
- Date last accessed
- Date last updated
- Owner id
- Protection information
Operation performed on directory are:
- Search for a file
- Create a file
- Delete a file
- List a directory
- Rename a file
- Traverse the file system
SINGLE-LEVEL DIRECTORY
In this a single directory is maintained for all the users
TWO-LEVEL DIRECTORY
Due to two levels there is a path name for every file to locate that file.
TREE-STRUCTURED DIRECTORY
Directory is maintained in the form of a tree. Searching is efficient and also there is grouping capability.
Disk scheduling
It is done by operating systems to schedule I/O requests arriving for the disk. Disk scheduling is also known as I/O scheduling.
- Seek Time: Seek time is the time taken to locate the disk arm to a specified track where the data is to be read or write. So the disk scheduling algorithm that gives minimum average seek time is better.
- Rotational Latency: Rotational Latency is the time taken by the desired sector of disk to rotate into a position so that it can access the read/write heads. So the disk scheduling algorithm that gives minimum rotational latency is better.
- Transfer Time: Transfer time is the time to transfer the data. It depends on the rotating speed of the disk and number of bytes to be transferred.
- Disk Access Time: Disk Access Time is:
Disk Scheduling Algorithms
- FCFS: FCFS is the simplest of all the Disk Scheduling Algorithms and is widely used due to its ease of implementation. This algorithm works by servicing requests according to their order of arrival in the disk queue, without any consideration of priority or the amount of time it may take to service the request. This means that requests are addressed in the order they arrive in the disk queue, with no prioritization of requests. This could potentially lead to starvation of certain requests, if they are continually pushed to the back of the queue by requests that arrive later. As such, FCFS can be inefficient in certain cases, where some requests require more time than others to service.
- SSTF: In SSTF (Shortest Seek Time First), requests having the shortest seek time are executed first, in order to minimize the total time taken for the disk arm to move from request to request. To accomplish this, the seek time of every request is calculated in advance and then stored in a queue for later use. This queue is then used to determine the order in which the requests will be served - requests with a shorter seek time will be served first, allowing the disk arm to quickly move to the next request, rather than having to move through a larger number of requests first. As a result, the request that is closest to the disk arm will be the first one to be serviced, reducing the total time taken to complete the jobs.
- SCAN: In SCAN algorithm, the disk arm moves in a particular direction and services all the requests it encounters in its path, until it reaches the end of the disk. At this point, the arm reverses its direction and again services the requests in its path. This algorithm works similar to an elevator, which is why it is also known as the elevator algorithm. What makes the SCAN algorithm unique is its ability to continually monitor the requests and service them quickly and efficiently, all while moving in one direction. This helps minimize the amount of time and energy spent on seeking out requests, thereby making the process more efficient and cost-effective.
- CSCAN: In the SCAN algorithm, the disk arm again scans the same path it has already gone over after reversing its direction. This means that it is possible that there may be too many requests waiting at the other end of the scanned path, or there may be zero or few requests pending at the area that has already been scanned. This repetition of the same scan can cause inefficiencies, as the disk arm will be spending too much time over an area that has already been searched, rather than moving on to areas that may have more requests. As a consequence, it is important to monitor the number of requests in order to make sure the disk arm is not wasting time on already scanned areas.
- LOOK: It is similar to the SCAN disk scheduling algorithm, however there is an important difference; instead of the disk arm travelling all the way to the end of the disk, it only travels as far as the last request to be serviced in front of the head, and then reverses its direction from there. This prevents the extra delay that would be caused by unnecessary traversal to the end of the disk, leading to improved performance and efficiency. This advantage is particularly beneficial in the context of time-sensitive applications, where the speed of completion is of the utmost importance.
- CLOOK: As LOOK is similar to SCAN algorithm, in a similar manner, CLOOK is analogous to CSCAN disk scheduling algorithm. In CLOOK, the disk arm instead of traversing to the end, only moves to the last request prior to the head, and then proceeds to the other end's last request. This prevents the additional delay caused by the unnecessary movement of the disk arm to the end of the disk. Furthermore, this strategy optimizes the disk scheduling process by cutting down on the time it takes to move the arm between requests. This makes CLOOK an efficient and effective disk scheduling algorithm.