


Data Structure
What is Data Structure?
A data structure is a specialized format for organizing, processing, retrieving and storing data. There are several basic and advanced types of data structures, all designed to arrange data to suit a specific purpose. Data structures make it easy for users to access and work with the data they need in appropriate ways.
Type of Data Structure
Linear
A linear data structure is a structure in which the elements are stored sequentially, and the elements are connected to the previous and the next element. As the elements are stored sequentially, so they can be traversed or accessed in a single run. The implementation of linear data structures is easier as the elements are sequentially organized in memory. The data elements in an array are traversed one after another and can access only one element at a time.
Non-Linear
A non-linear data structure is also another type of data structure in which the data elements are not arranged in a contiguous manner. As the arrangement is non-sequential, so the data elements cannot be traversed or accessed in a single run. In the case of linear data structure, element is connected to two elements (previous and the next element), whereas, in the non-linear data structure, an element can be connected to more than two elements.
Big-O Notation
What is Big-O Notation?
is a standard mathematical notation that shows how efficient an algorithm is in the worst-case scenario relative to its input size. To measure the efficiency of an algorithm, we need to consider two things:
- Time Complexity: How much time does it take to run completely?
- Space Complexity: How much extra space does it require in the process?
Terms in Big-O Notations:
- describes the upper bound of the complexity.
- describes the lower bound of the complexity.
- describes the exact bound of the complexity.
- describes the upper bound excluding the exact bound.
- means in constant time - independent of the number of items.
- means in proportion to the number of items.
- means a time proportional to .




Sorting Algorithms


Linked List
A linked list is a linear data structure where elements are not stored at contiguous location. Instead the elements are linked using pointers.
Bubble Sort
Bubble sort, sometimes referred to as sinking sort, is a simple sorting algorithm that repeatedly steps through the list, compares adjacent elements and swaps them if they are in the wrong order.
Insertion Sort
Insertion sort is a simple sorting algorithm that builds the final sorted array one item at a time.
Selection Sort
The selection sort algorithm sorts an array by repeatedly finding the minimum element (considering ascending order) from unsorted part and putting it at the beginning.
Abstract Data Type
The ADT's are generalizations of primitive data type(integer, char etc) and they encapsulate a data type in the sense that the definition of the type and all operations on that type localized to one section of the program. They are treated as a primitive data type outside the section in which the ADT and its operations are defined.
Stack
Stack is a linear data structure which follows a particular order in which the operations are performed. The order may be LIFO (Last-In-First-Out) or FILO (First-In-Last-Out).
Queue
Queue is the data structure that is similar to the queue in the real world. A queue is a data structure in which whatever comes first will go out first, and it follows the FIFO policy. Queue can also be defined as the list or collection in which the insertion is done from one end known as the rear end or the tail of the queue, whereas the deletion is done from another end known as the front end or the head of the queue.
- Enqueue: The Enqueue operation is used to insert the element at the rear end of the queue. It returns void.
- Dequeue: It performs the deletion from the front-end of the queue. It also returns the element which has been removed from the front-end. It returns an integer value.
- Peek: This is the third operation that returns the element, which is pointed by the front pointer in the queue but does not delete it.
- Queue overflow : It shows the overflow condition when the queue is completely full.
- Queue underflow : It shows the underflow condition when the Queue is empty, i.e., no elements are in the Queue.
Simple Queue or Linear Queue
In Linear Queue, an insertion takes place from one end while the deletion occurs from another end. The end at which the insertion takes place is known as the rear end, and the end at which the deletion takes place is known as front end. It strictly follows the FIFO rule.
Circular Queue
In Circular Queue, all the nodes are represented as circular. It is similar to the linear Queue except that the last element of the queue is connected to the first element. It is also known as Ring Buffer, as all the ends are connected to another end.
Priority Queue
It is a special type of queue in which the elements are arranged based on the priority. It is a special type of queue data structure in which every element has a priority associated with it. Suppose some elements occur with the same priority, they will be arranged according to the FIFO principle.
Node
Nodes are a basic data structure which contain data and one or more links to other nodes. Nodes can be used to represent a tree structure or a linked list. In such structures where nodes are used, it is possible to traverse from one node to another node.
Orphaned nodes
Nodes that have no links pointing to them except for the head node, are considered “orphaned.”
Implementing Node in Python
class Node: def __init__(self, value, next_node=None): self.value = value self.next_node = next_node def set_next_node(self, next_node): self.next_node = next_node def get_next_node(self): return self.next_node def get_value(self): return self.value
Hash Table
A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
Hashing Function
A hash function maps keys to small integers (buckets). An ideal hash function maps the keys to the integers in a random-like manner, so that bucket values are evenly distributed even if there are regularities in the input data.
This process can be divided into two steps:
- Map the key to an integer.
- Map the integer to a bucket.
Tree
A tree is non-linear and a hierarchical data structure consisting of a collection of nodes such that each node of the tree stores a value and a list of references to other nodes (the “children”).
Terms:
- Root - Root node is a node from which the entire tree originates. It does not have a parent.
- Parent Node - An immediate predecessor of any node is its parent node.
- Child Node - All immediate successors of a node are its children. The relationship between the parent and child is considered as the parent-child relationship.
- Leaf - Node which does not have any child is a leaf. Usually the boundary nodes of a tree or last nodes of the tree are the leaf or collectively called leaves of the tree.
- Height of Node - Height of a node represents the number of edges on the longest path between that node and a leaf.
- Sub-tree - Any node of the tree along with its descendant
Binary Tree
A tree whose elements have at most 2 children is called a Binary Tree.

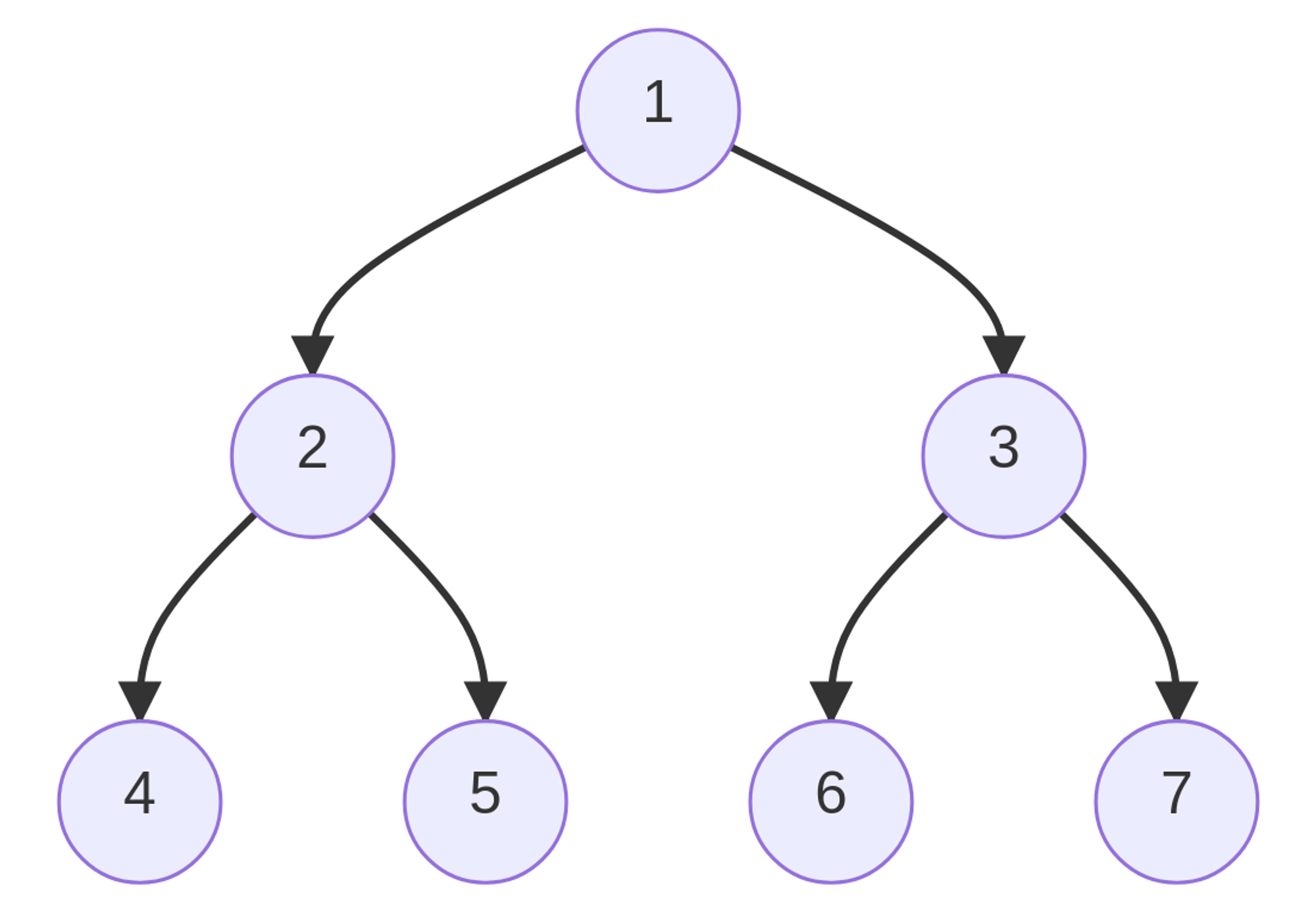
Strict/Full Binary Tree
A full Binary tree is a special type of binary tree in which every parent node/internal node has either two or no children.
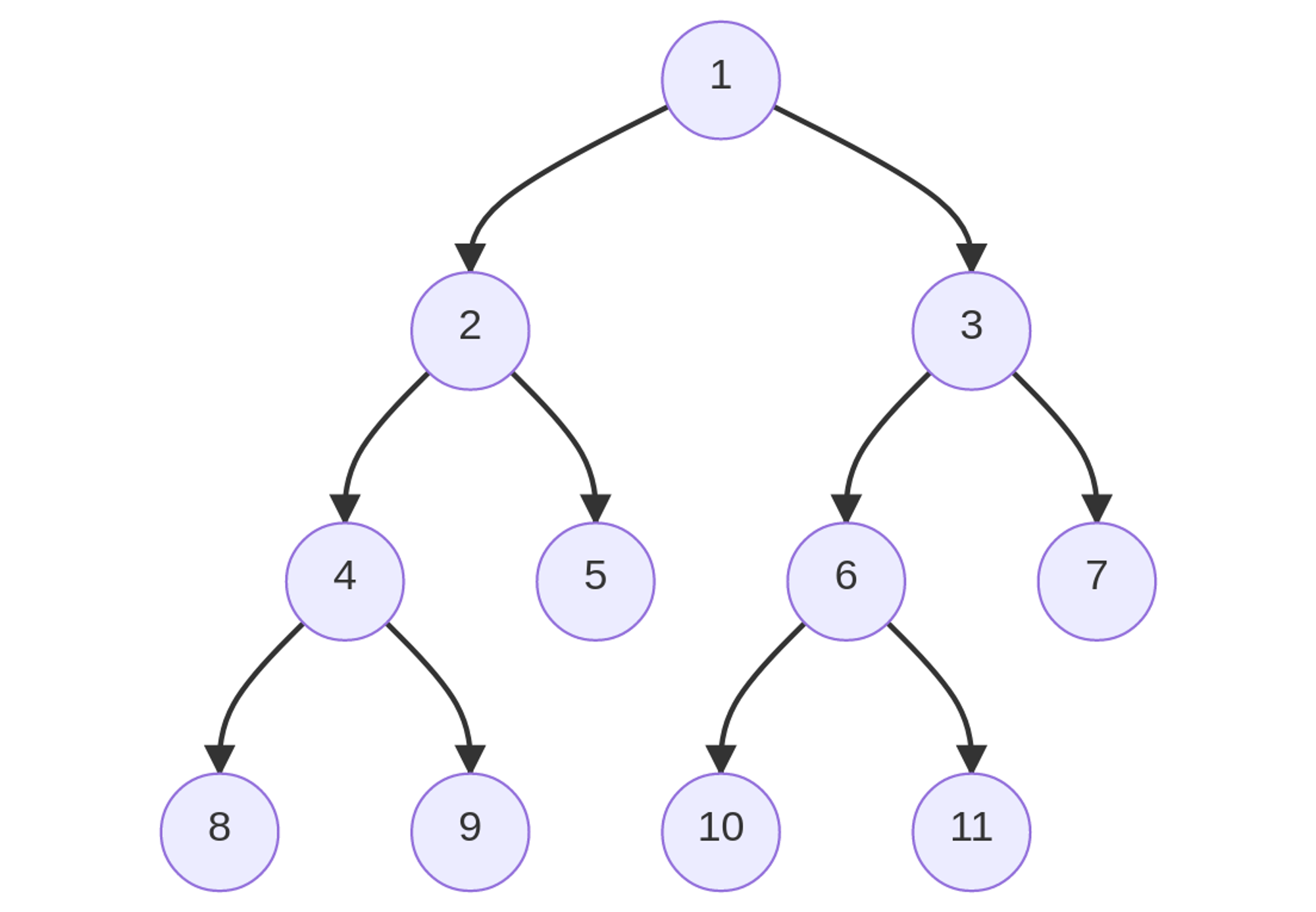
Complete Binary Tree
A complete binary tree is just like a full binary tree, but with two major differences
- Every level must be completely filled
- All the leaf elements must lean towards the left.
- The last leaf element might not have a right sibling i.e. a complete binary tree doesn't have to be a full binary tree.
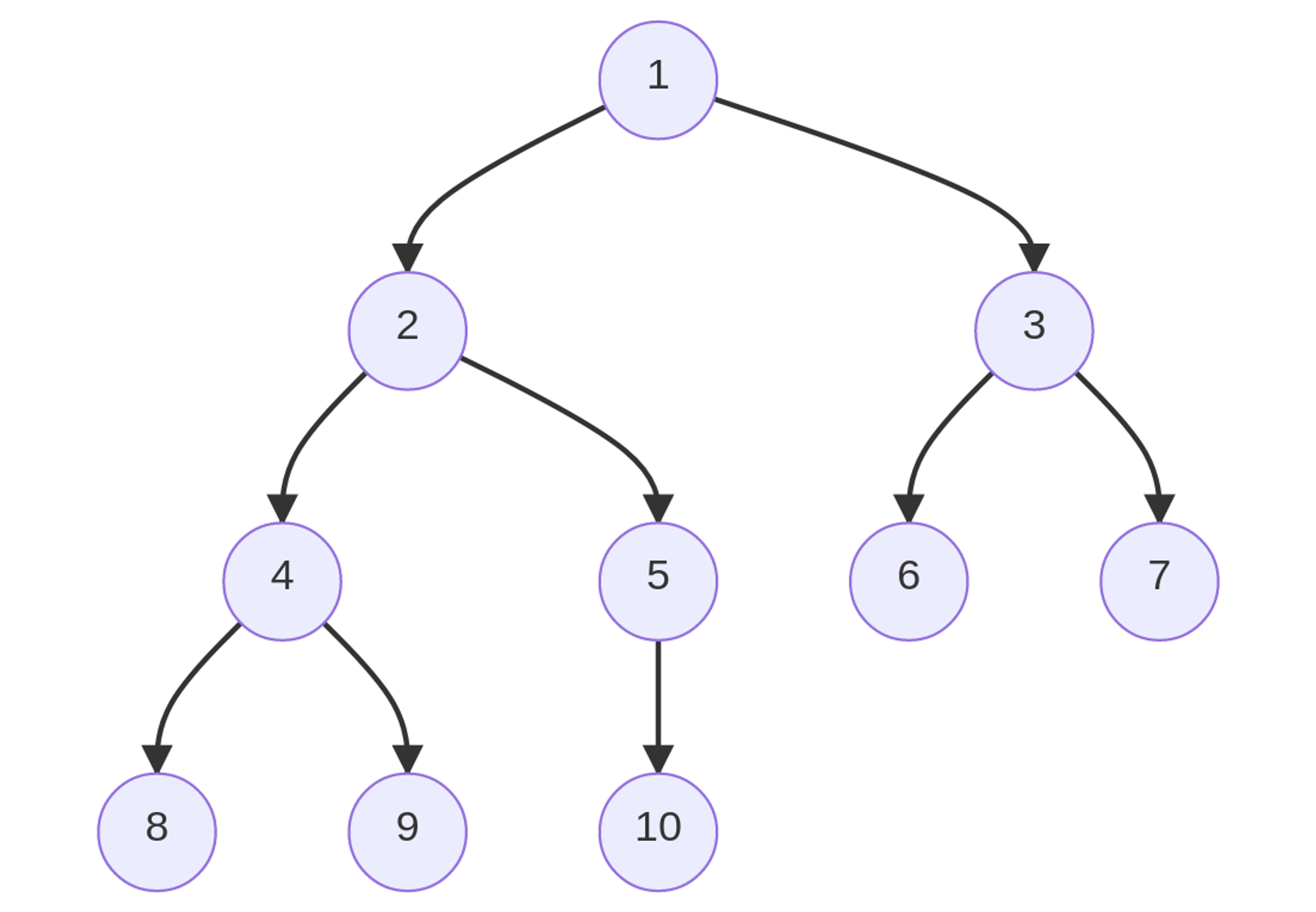
Balanced Binary Tree
It is a type of binary tree in which the difference between the height of the left and the right sub-tree for each node is either 0 or 1.
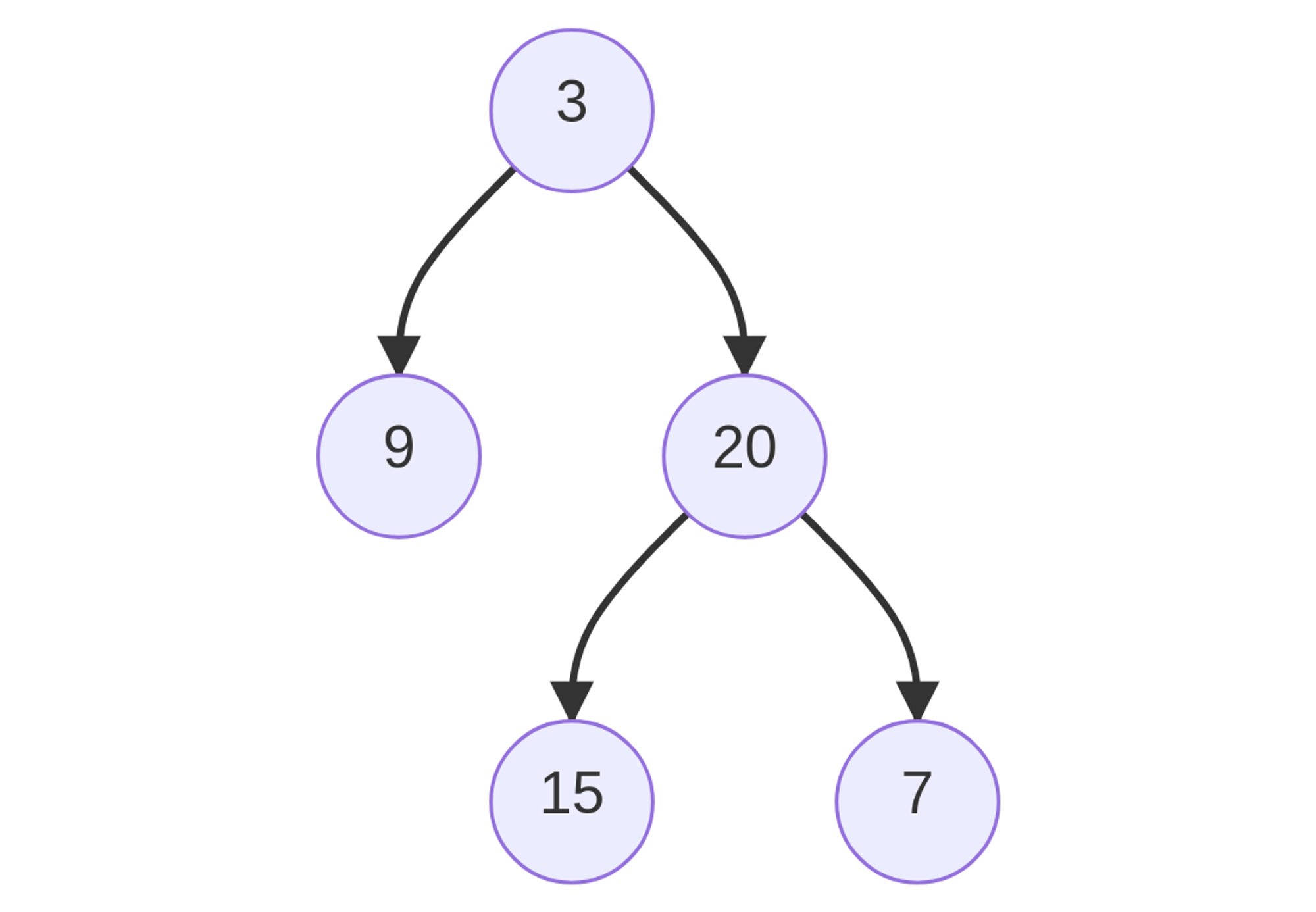
Implementing Tree in Python
class TreeNode: def __int__(self, data, left_node=None, right_node=None): self.data = data self.left = left_node self.right = right_node
Inserting in Tree
def insert(self, data): if self.data: if data < self.data: if self
Printing Tree
def printTree(root): if root == None: return
Balancing Tree
Tree Traversal
It is a form of graph traversal and refers to the process of visiting (e.g. retrieving, updating, or deleting) each node in a tree.
In-order
- Recursively traverse the current node's left sub-tree.
- Visit the current node.
- Recursively traverse the current node's right sub-tree.
Pre-order
- Visit the current node.
- Recursively traverse the current node's right sub-tree.
- Recursively traverse the current node's left sub-tree.
Post-order
- Recursively traverse the current node's right sub-tree.
- Recursively traverse the current node's left sub-tree.
- Visit the current node.
AVL Trees
AVL tree (named after inventors Adelson-Velsky and Landis) is a self-balancing Binary Search Tree (BST) where the difference between heights of left and right sub-trees cannot be more than one for all nodes.
Balance Factor
The balance factor in AVL Trees is an additional value associated with each node of the tree that represents the height difference between the left and the right sub-trees of a given node. The balance factor of a given node can be represented as:
AVL Tree Rotation
It is the process of changing the structure of the tree by moving smaller sub-trees down and larger sub-trees up, without interfering with the order of the elements.
Single Right Rotation
In left rotations, every node moves one position to left from the current position.
Single Left Rotation
In right rotations, every node moves one position to right from the current position.
Left-Right Ration
Left-right rotations are a combination of a single left rotation followed by a single right rotation.
Right-Left Rotation
Right-left rotations are a combination of a single right rotation followed by a single left rotation.
Graph
A graph data structure is a non-linear collection of nodes that are connected together, each containing data or information. It is a powerful structure that can be used to model many types of relationships. For example, it can be used to represent the relationships between people, or the connections between cities in a map. Graphs can also be used to represent abstract concepts, such as the structure of a computer program or the structure of a network. They are composed of vertices and edges, which are used to represent the nodes and the connections between them. Graphs are an incredibly useful tool that can be used to solve a wide range of problems.
Terms:
- Path - A path in a graph is a finite or infinite set of edges which joins a set of vertices. It can connect to 2 or more nodes
- Closed Path - A path is called as closed path if the initial node is same as terminal(end) node.
- Simple Path - A path that does not repeat any nodes(vertices) is called a simple path.
- Degree of a Node - Degree of a node is the number of edges connecting the node in the graph.
- Cycle Graph - A simple graph of ‘n’ nodes(vertices) (n>=3) and n edges forming a cycle of length ‘n’ is called as a cycle graph. In a cycle graph, all the vertices are of degree 2.
- Connected Graph - Connected graph is a graph in which there is an edge or path joining each pair of vertices.
- Complete Graph - In a complete graph, there is an edge between every single pair of node in the graph.
- Weighted Graph - In weighted graphs, each edge has a value associated with them (called weight). It refers to a simple graph that has weighted edges. The weights are usually used to compute the shortest path in the graph.
- Simple Graph - A graph having no self loops and no parallel edges in it is called as a simple graph.
Huffman Coding
Huffman Coding is a technique of compressing data to reduce its size without losing any of the details. It was first developed by David Huffman.
Huffman Coding is generally useful to compress the data in which there are frequently occurring characters.
Classification of Design Patterns
Design Patterns are categorized mainly into three categories: Creational Design Pattern, Structural Design Pattern, and Behavioral Design Pattern. These are differed from each other on the basis of their level of detail, complexity, and scale of applicability to the entire system being design.
Creational Design Pattern
As the name suggests, it provides the object or classes creation mechanism that enhance the flexibility and re-usability of the existing code. They reduce the dependency and controlling how the use interaction with our class so we wouldn't deal with the complex construction. Below are the various design pattern of creational design pattern.
- Abstract Factory- It allows us to create objects without specifying their concrete type.
- Builder - It is used to create the complex objects.
- Factory Method - It allows us to create object without specifying the exact class to create.
- Prototype - It is used to create a new object from the existing object.
- Singleton - Singleton design pattern make sure that there is only one instance of an object is created.
Structural Design Patterns
Structural Design Patterns mainly responsible for assemble object and classes into a larger structure making sure that these structure should be flexible and efficient. They are very essential for enhancing readability and maintainability of the code. It also ensure that functionalities are properly separated, encapsulated. It reduces the minimal interface between interdependent things.
- Adapter - It provides us for two incompatible classes to work together by wrapping an interface around one of the existing classes.
- Composite - It wraps a group of objects into a single object.
- Bridge - It decouples an abstraction so that two classes can vary independently.
- Decorator - It extends the object behavior dynamically at the run time.
- Facade - It offers a simple interface to more complex underlying objects.
- Flyweight - It decreases the cost of complex object model.
- Proxy - It reduces the cost, reduce complexity, and provide the placeholder interface to an underlying object to control access.
Behavior Design Pattern
Behavior Design Patterns are responsible for how one class communicates with others.
- Chain of Responsibility - It representatives the command to a chain of processing object.
- Command - It generates the objects which encapsulate actions of parameters.
- Interpreter - It implements a specialized language.
- Iterator - It accesses all the element of an object sequentially without violating its underlying representation.
- Mediator - It provides the loose coupling between classes by being the only class that has detailed knowledge of their existing methods.
- Memento - It restores an object in the previous state.
- Observer - It allows a number of observer objects to see an event.
- State - It allows an object to modify its behavior when it's internal states changes.
- Strategy - It provides one of the families of algorithm to be selected at the runtime.
- Template Method - It allows the sub-classes to provide concrete behavior. It also defines the skeleton of an algorithm as an abstract class.
- Visitor - It separates an algorithm from an object structure by moving the hierarchy of methods into one object.